Sebelumnya kami membut Expert system mengenai absen sidik jari dan pemindaian mata. Tapi, hal itu sangat sulit untuk di buat ke dalam Prolog. Maka dari itu, kami membuat konsep Expert System yang baru. Expert System kali ini lebih simple, yaitu mengenai Pencarian Resep-Resep Kue Tradisional Indonesia.
Kami membuat Expert System bertajuk Development of Simple Expert System for Finding Recipe of Traditional Indonesian Cake.
Untuk pembuatan dalam prolognya, sebelumnya anda mendeklarasikannya ke dalam notepad seperti ini
Setelah itu consult dalam prolog, dan apabila ingin mencari resep, tuliskan find(resepkue). ,contoh : find(serabi).
Sekarang, kita akan membahas tentang Looping dalam Prolog. Seperti kita ketahui, sebagian besar bahasa pemrograman konvensional memiliki fasilitas yang memungkinkan perulangan satu set instruksi ke b dilaksanakan untuk beberapa kali, atau sampai suatu kondisi terpenuhi. Meskipun, Prolog tidak memiliki fasilitas perulangan, perulangan efek serupa dapat dilakukan dalam beberapa beberapa cara, menggunakan backtracking, rekursi, built-in predikat, atau kombinasi dari itu.
Looping a Fixed Number of Times
Tidak seperti java, yang memiliki fasilitas untuk-loop untuk mengaktifkan satu set instruksi yang akan dieksekusi nomor tetap kali, Prolog tidak tersedia untuk melakukan hal itu (langsung), tapi efek yang sama dapat diperoleh dengan menggunakan rekursi, seperti:
testloop(0).
testloop(N) :- N>0, write(‘Number : ‘), write(N), nl, M is N-1, testloop(M)
Testloop predikat yang didefinisikan sebagai 'loop dari N, tulis nilai N, kemudian kurangi satu untuk diberikan kepada M, kemudian loop dari M'. "Dan oleh klausa pertama, didefinisikan sebagai 'jika argumen adalah nol, melakukan apa-apa (stop!)'. uji program:
?- testloop(3). Number : 3 Number :2 Number :1
yes
Looping until a Condition is Satisfied
Contoh di bawah ini menunjukkan penggunaan istilah rekursi untuk membaca dimasukkan oleh pengguna dari keyboard dan output mereka ke layar, sampai akhir adalah sebuah kata yang dihadapi, dengan menggunakan ‘disjunctive goal’(word=end).
test :- write(‘Type the word : ‘), read(word), write(‘Input was ‘), write(word), nl, (word=end; test).
?- test.
Type the word : Hello.
Input was Hello
Type the word : ITS.
Input was ITS
Type the word : end.
Input was end.
yes
Backtracking with failure
Seperti namanya, predikat gagal, selalu gagal, apakah pada 'standar' evaluasi kiri ke kanan atau pada kemunduran. Dengan menggabungkan dengan otomatis Prolog backtracking, untuk mencari database untuk menemukan semua klausa dengan properti khusus, kita dapat memiliki perulangan otomatis.
Contoh program di bawah ini dirancang untuk mencari database yang berisi klausul yang mewakili nama, umur, tempat tinggal, dan pekerjaan dari sejumlah orang.
Database berisi nilai-nilai ini:
person(john,smith,45,london,doctor).
person(martin,williams,33,birmingham,teacher).
person(henry,smith,26,manchester,plumber).
person(jane,wilson,62,london,teacher).
person(mary,smith,29,glasgow,surveyor).
predikat Somepeople di bawah ini adalah untuk pencarian orang dalam database yang merupakan nama keluarga smith
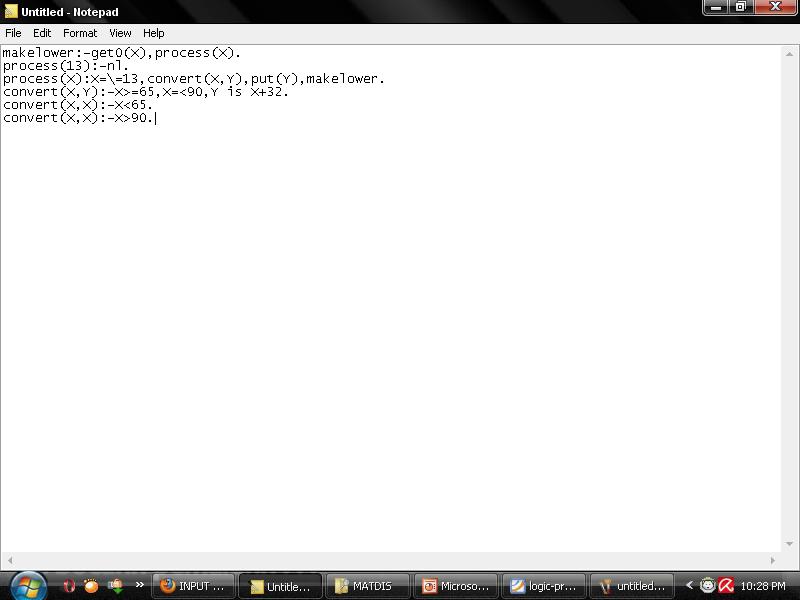
Define a predicate makelower/0 which reads in a line of characters from the
keyboard and outputs it again as a single line with any upper case letters converted
to lower case. (The ASCII values of the characters a, z, A and Z are 97, 122, 65 and
90, respectively.)
Thus the following would be a typical use of makelower:
?- makelower.
: This is an Example 123 inCLUDing numbers and symbols +-*/@[] XYz
this is an example 123 including numbers and symbols +-*/@[] xyz
yes
JAWAB
1. deklarasikan dan simpan dengan format .pl
2. lalu buka file tadi
3. lalu ketikkan kata makelower. (akhiri dengan tanda titik), setelah itu tuliskan kata-kata terserah anda, huruf besar kecil juga boleh
hasilnya adalah, semua huruf besar yang ditulis menjadi kecil
SOAL 2
Define a predicate copyterms which reads all the terms in a text file and
outputs them as terms to another text file one by one on separate lines.
The output file should be in a format suitable for use as the input file in a
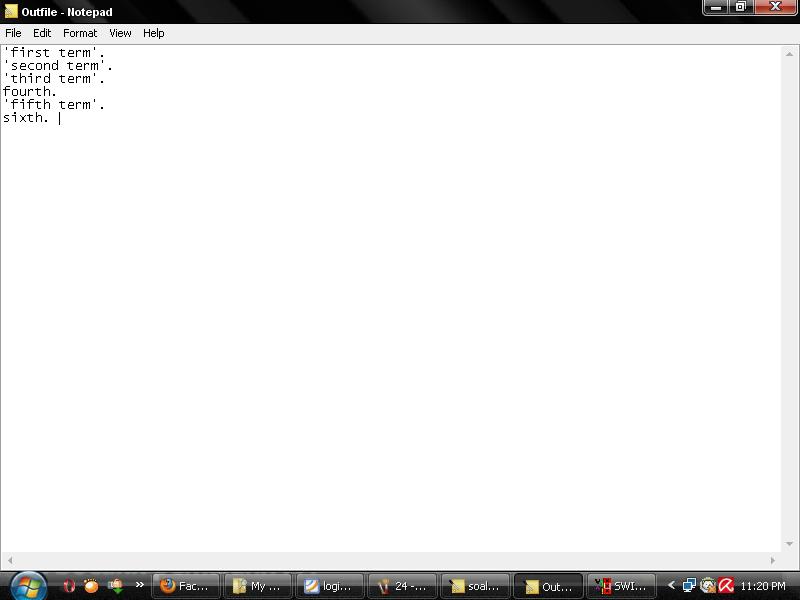
subsequent call of copyterms. Thus for example if the input file contained
'first term'. 'second term'.
'third term'.
fourth. 'fifth term'.
sixth.
The output file would contain
'first term'.
'second term'.
'third term'.
fourth.
'fifth term'.
sixth.
JAWAB
1. deklarasikan dan simpan dengan format pl
2. buat file baru bernama Infile.txt, isinya seperti berikut
3. Lalu buka file berformat .pl tadi
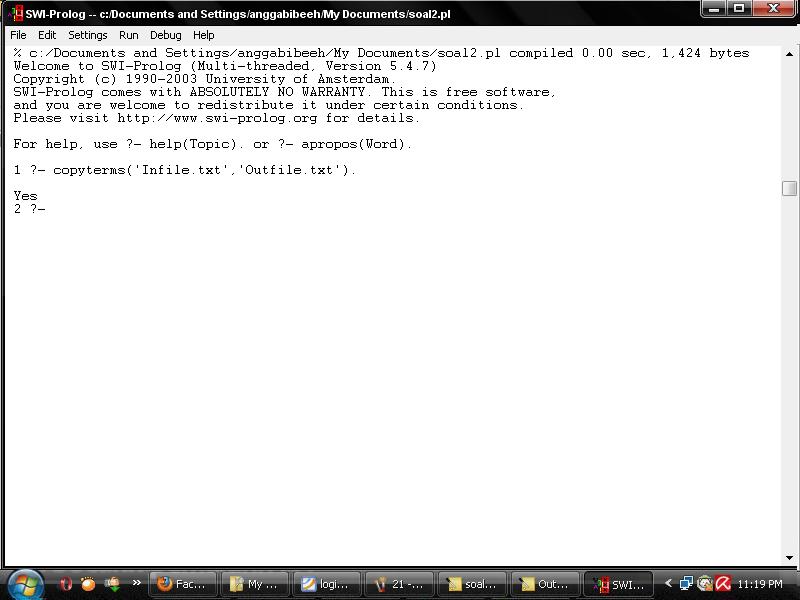
4. Setelah itu ketikkan copyterms('Infile.txt','Outfile.txt').
5. hasilnya akan keluar di file baru bernama Outfile.txt, yang berisi seperti ini
SOAL 3
Create a text file testa.txt containing two lines, each of five characters followed
by a new line, e.g.
abcde
fghij
Define a predicate readfile that will read fifteen characters from this file one by
one and output the ASCII value of each character. Use this to establish whether the Input and Output 83
representations of 'end of file' and 'end of record' for your version of Prolog are as
suggested in Sections 5.9.1 and 5.9.2, respectively.
JAWAB
1. deklarasikan lalu simpan dengan fromat .pl
2. lalu buat file testa.txt yang berisi seperti di bawah
3. setelah itu buka file berformat .pl tadi
4. Setelah itu ketikkan readfile('testa.txt'). hasilnya adalah seperti ini
SOAL 4
Using a text editor, create two text files in1.txt and in2.txt, each comprising a
number of terms terminated by end.
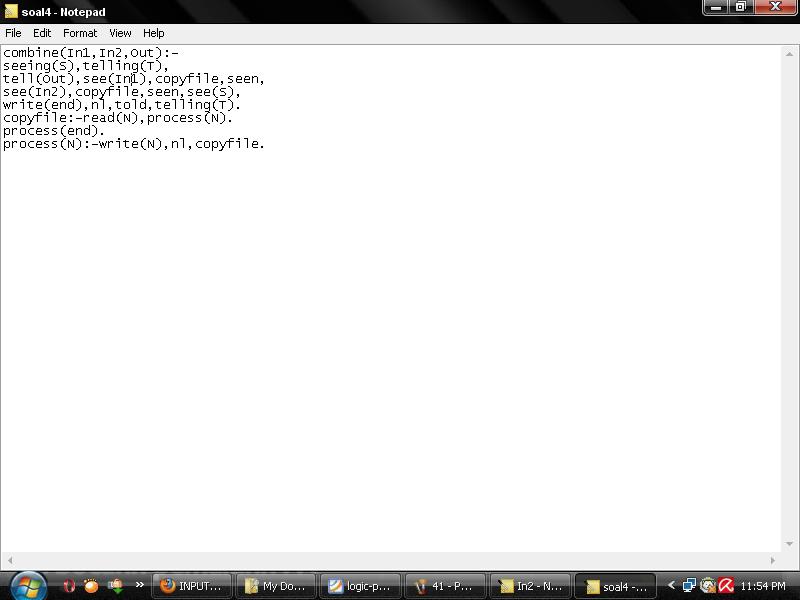
Define and test a predicate combine that takes the names of two input files as its
first two arguments and the name of an output file as its third argument. The output
file should contain the terms in the first input file followed by the terms in the
second, one per line and terminated by end.
JAWAB
1. deklarasikan dan simpan dengan format .pl
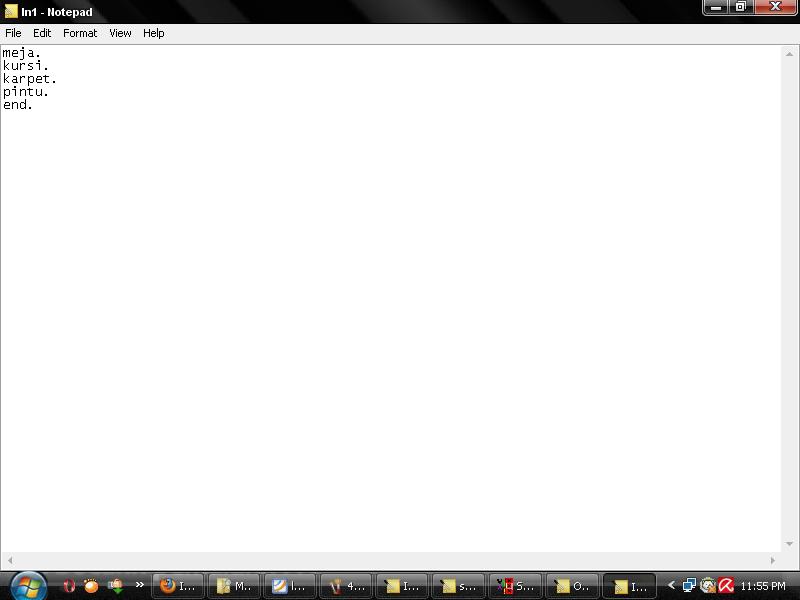
2. Buat s file lagi, yang satu bernama In1.txt dan yang kedua bernama In2.txt. Isinya lihat di bawah ini (bisa berubah-ubah)
3. lalu buka file yang berformat .pl tadi
4. Setelah itu tuliskan combine('In1.txt','In2.txt','Out.txt').
5. Hasilnya akan muncul file baru bernama Out.txt dan isinya adalah gabungan antara In1 dan In2 seperti ini
SOAL 5
Define and test a predicate compare that reads in two text files term by term
and for each pair of corresponding terms outputs a message either saying that they
are the same or that they are different. Assume that both files contain the same
number of terms and that the final term in each is end.
JAWAB
1. deklarasikan dan simpan dalam format .pl
2. Lalu buat file bernama Satu.txt dan Dua.txt, isinya seperti di bawah ini
5. setelah itu buka file berformat .pl tadi, dan ketikkan compare('Satu.txt','Dua.txt'). maka hasilnya akan seperti berikut
built-in predikat yang membaca dari dan menulis baik untuk pengguna
terminal (keyboard dan layar) atau file, kedua istilah tersebut dengan istilah dan characterby -
karakter dalam program Anda sendiri. nilai ASCII untuk memanipulasi string karakter. Menggunakan istilah lebih sederhana dan akan dijelaskan terlebih dahulu. Awalnya, maka akan diasumsikan bahwa
semua output ke layar pengguna dan semua input adalah dari pengguna keyboard. Masukan dan keluaran menggunakan file eksternal.
Syarat keluaran
predikat mengambil satu argumen, yang harus yang valid Prolog istilah. Mengevaluasi menyebabkan predikat istilah yang akan ditulis ke arus keluaran
sungai, yang secara default adalah layar pengguna. (Yang dimaksud dengan arus keluaran Dengan Logika Pemrograman Prolog
Built-in predikat membaca disediakan untuk memasukkan istilah. Dibutuhkan satu argumen, yang harus menjadi variabel.
Mengevaluasi itu menyebabkan istilah berikutnya untuk dibaca dari input arus sungai,
yang secara default adalah pengguna keyboard. (Yang dimaksud dengan arus input). Dalam input stream, istilah harus diikuti oleh sebuah titik ('.') dan setidaknya satu spasi, seperti spasi atau baris baru. Titik dan spasi karakter dibaca dalam tetapi tidak dianggap bagian dari istilah. Perhatikan bahwa untuk masukan dari keyboard (hanya) sebuah prompt karakter seperti titik dua biasanya akan ditampilkan untuk menunjukkan bahwa input pengguna diperlukan. Mungkin perlu untuk tekan tombol 'kembali' tombol sebelum Prolog akan menerima input. Kedua tidak berlaku untuk masukan dari file. Ketika sebuah tujuan membaca dievaluasi, istilah input disatukan dengan argumen variabel. Jika variabel tidak terikat (yang biasanya terjadi) itu adalah terikat pada masukan nilai.
Contoh
? - Read (X).
: Jim.
X = jim
? - Read (X).
: 26.
X = 26
? - Read (X).
: Mypred (a, b, c).
X = mypred (a, b, c)
? - Read (Z).
: [A, b, mypred (p, q, r), [z, y, x]].
Z = [a, b, mypred (p, q, r), [z, y, x]]
? - Read (Y).
: 'String karakter'.
Y = 'string karakter'
Input dan Output Menggunakan Karakter
Meskipun input dan output dari syarat-syarat sangat mudah, penggunaan tanda kutip dan penuh berhenti dapat menjadi rumit dan tidak selalu sesuai. Sebagai contoh, akan membosankan untuk menentukan predikat (menggunakan baca) yang akan membaca serangkaian karakter dari keyboard dan menghitung jumlah huruf vokal. Sebuah pendekatan yang lebih baik untuk masalah semacam ini adalah untuk masukan sebuah karakter pada satu waktu. Untuk melakukan hal ini, pertama-tama perlu
untuk mengetahui tentang nilai ASCII karakter. Semua mencetak karakter dan banyak karakter non-cetak (seperti ruang dan tab) memiliki sesuai ASCII (American Standard Kode untuk Informasi Interchange) nilai, yang merupakan integer 0-255. Nilai ASCII karakter yang kurang dari atau sama dengan 32 yang dikenal sebagai putih ruang karakter.
Keluaran karakter
Karakter adalah output dengan menggunakan built-in predikat meletakkan predikat mengambil argumen tunggal, yang harus menjadi nomor 0-255 atau ekspresi yang
mengevaluasi ke integer dalam jangkauan. Mengevaluasi tujuan put menyebabkan satu karakter untuk menjadi output untuk saat ini output stream. Ini adalah karakter yang sesuai dengan nilai numerik (ASCII nilai) dari argumen.
misalnya
? - Meletakkan (97), nl.
sebuah
ya
? - Meletakkan (122), nl.
z
ya
? - Meletakkan (64), nl.
@
ya
Output ke sebuah File
Meskipun definisi di atas kirim menyatakan bahwa 'semua file yang sudah ada dengan yang sama Namanya dihapus ', ada kemungkinan lain, yang penting bagi beberapa aplikasi, yaitu bahwa file tersebut tidak dihapus dan setiap output ditempatkan setelah akhir isi yang ada file. Baik 'menimpa' dan 'append' pilihan
kemungkinan besar akan tersedia dalam pelaksanaan praktis Prolog tetapi mungkin melibatkan menggunakan predikat yang berbeda (misalnya terbuka) sebagai pengganti atau serta kirim.
Input: Mengubah Input Current Stream
Input stream yang aktif dapat diubah dengan menggunakan melihat / 1 predikat. Ini membutuhkan argumen tunggal, yang merupakan atom atau variabel yang mewakili nama file, misalnya lihat ( 'myfile.txt'). Mengevaluasi sebuah tujuan melihat menyebabkan file bernama input yang menjadi sungai. Jika file ini belum terbuka itu pertama kali dibuka (untuk akses baca saja). Jika tidak mungkin untuk membuka file dengan nama yang diberikan, kesalahan akan dihasilkan.
Penerapan Expert System dengan Menggunakan Sistem identifikasi suara dan sidik jari sebagai absen kehadiran
Latar belakang
Dewasa ini, sistem absensi dengan cara tandatangan dirasa kurang optimal dalam penjalanannya. Banyak sekali siswa, mahasiswa hingga pegawai karyawan suka membolos dan terlambat masuk. Seperti yang kita ketahui sekarang ini, sistem absensi tandatangan yang diberlakukan di kampus jurusan Sistem Informasi ITS sangat menguntungkan mahasiswa yang biasanya malas kuliah. Banyak dari mereka yang menggampangkan jadwal kuliah, hingga mereka sering sekali datang tidak tepat waktu. Bahkan, parahnya lagi, mereka seringkali titip absen kepada teman mereka yang biasanya rajin masuk kuliah. Hal, ini sangat berpengaruh buruk bagi siswa yang sering titip absen (TA) ini, karena mereka akan ketinggalan materi kuliah dan tidak tahu apa-apa tentang materi yang dibahas. Walaupun absen mereka penuh, tapi mereka tidak mendapatkan apa-apa. Bahkan TA ini lebih buruknya lagi menjadi budaya mahasiswa sekarang ini. Sama halnya dengan mahasiswa, para karyawan baik swasta maupun negeri biasanya sering datang terlambat ke kantor, karena mereka menganggap absensi itu yang penting ada. Beberapa kantor sudah menerapkan sistem absensi check lock yang didalamnya terdapat waktu kedatangan para karyawan tersebut. Hal ini sebenarnya memang sudah bagus, tapi masih ada juga beberapa karyawan yang mengakalinya dengan titip kepada temannya. Apabila hal ini terus menerus dilakukan, maka keterlambatan dan membolos akan menjadi budaya bangsa Indonesia.
Tujuan
Menjadikan disiplin dan tegas dalam bekerja dan belajara merupakan hal yang utama dalam menjalankan keseharian. Supaya keterlambatan dan membolos itu tidak menjadi budaya yang buruk bagi Bangsa Indonesia
Penjelasan
Sistem absensi dengan menggunakan suara dan sidik jari ini diterapkan pada seluruh kantor dan di setiap ruang kelas pada kampus. Setiap ruang dipasang alat pendeteksi suara dan sidik jari yang kemudian dihubungkan ke operator pusat. Fungsi operator pusat ini adalah untuk memantau, mendeteksi serta mencatat kehadiran dari mahasiswa atau pegawai yang datang. Dengan hal ini, maka budaya titip absen atau yang biasa disebut dengan TA tidak akan terjadi lagi.
(1) This program is based on Animals Program 3, given in Chapter 2.
dog(fido). large(fido).
cat(mary). large(mary).
dog(rover). small(rover).
cat(jane). small(jane).
dog(tom). small(tom).
cat(harry).
dog(fred). large(fred).
cat(henry). large(henry).
cat(bill).
cat(steve). large(steve).
large(jim).
large(mike).
large_dog(X):- dog(X),large(X).
small_animal(A):- dog(A),small(A).
small_animal(B):- cat(B),small(B).
chases(X,Y):-
large_dog(X),small_animal(Y),
write(X),write(' chases '),write(Y),nl.
Convert the seven predicates used to operator form and test your revised program.
The output should be the same as the output from the program above. Include
directives to define the operators in your program.
Langkah-Langkah
1. kita diperintah untuk mengonvert predikat menggunakan operator form seperti yang ada pada contoh. Dan hasilnya harus sama dengan program yang ada pada contoh. Jadi yang kita menuliskan soal pada notepad dengan format .pl
Yang awalnya seperti ini:
2. Setelah itu kita mengubah notepad pada program yang pertama dengan suatu rule yang baru
3. Setelah itu buka file yang telah disimpan dalam format .pl tadi
4. Setelah itu ketikkan chases(X,Y). untuk melihat hasilnya. Dan tekan ; (titik koma) sampai keluar kata NO
5. Hasilnya pun sama dengan kita memakai rule yang ada di soal dengan rule yang telah kita buat sendiri
SOAL 2
(2) Define and test a predicate which takes two arguments, both numbers, and
calculates and outputs the following values: (a) their average, (b) the square root of
their product and (c) the larger of (a) and (b).
Langkah-Langkah
1. Melakukan hitungan rata-rata dari 2 buah bilangan.
Misal: X=45
Y=53
Maka kita mencari Z dengan rumus rata-rata yaitu (X+Y)/2
2. Menghitung akar dari hasil rata-rata tersebut. Maka kita mencari I dengan sqrt(Z).
3. Menentukan hasil yang paling besar dari 2 perhitungan sebelumnya. Maka kita mencari J dengan max(Z,I).
Operator
notasi yang digunakan untuk predikat adalah salah satu dari standar
functor diikuti oleh sejumlah argumen dalam kurung, misalnya suka (john, mary).
Sebagai alternatif, apapun predikat yang ditetapkan pengguna dengan dua argumen (binary predikat) dapat dikonversi ke operator infiks. Hal ini memungkinkan functor
(predikat nama) yang akan ditulis di antara dua argumen tanpa tanda kurung, misalnya
john suka mary. Setiap predikat yang ditetapkan pengguna dengan satu argumen (a unary predikat)dapat diubah menjadi prefiks operator. Hal ini memungkinkan untuk functor ditulis sebelum argumen tanpa tanda kurung. Notasi operator juga dapat digunakan dengan mudah dibaca aturan untuk bantuan. Setiap predikat yang ditetapkan pengguna dengan satu atau dua argumen dapat dikonversi ke operator dengan memasukkan tujuan menggunakan op predikat pada sistem prompt.
relasional operator untuk membandingkan nilai numerik, termasuk
daripada 'dan> menunjukkan' lebih besar dari '.
Jadi istilah berikut adalah valid, yang dapat dimasukkan ke dalam tubuh seorang
aturan:
X> 4
Y
A = B
Notasi tanda kurung juga dapat digunakan dengan built-in predikat yang didefinisikan sebagai
operator, e.g. > (X, 4) bukan X> 4.
Arithmetic
Meskipun contoh-contoh yang digunakan dalam bab-bab sebelumnya buku ini adalah non-numerik(hewan yang mamalia dll), Prolog juga menyediakan fasilitas untuk melakukan aritmatika menggunakan notasi yang serupa dengan yang sudah akrab bagi banyak pengguna dari aljabar dasar. Hal ini dicapai dengan menggunakan built-in predikat adalah / 2, yang telah ditetapkan sebagai infiks operator dan dengan demikian ditulis antara dua argumen. Cara yang paling umum adalah menggunakan / 2 adalah dimana argumen pertama adalah terikat variabel. Mengevaluasi tujuan X -6,5 akan menyebabkan X untuk terikat dengan jumlah -6,5 dan tujuan untuk sukses.
Argumen kedua dapat berupa nomor atau ekspresi aritmatika misalnya
X adalah 6 * Y + Z-3.2 + P-Q / 4 (* menandakan perkalian).
Setiap variabel yang muncul dalam sebuah ekspresi aritmatika sudah harus terikat(sebagai mengevaluasi hasil dari tujuan sebelumnya) dan nilai-nilai mereka harus numerik. Disediakan Dengan 60 Logika Pemrograman Prolog
mereka, tujuan akan selalu berhasil dan variabel yang membentuk pertama
argumen akan terikat dengan nilai ekspresi aritmetik. Jika tidak, kesalahan
pesan akan muncul.
? - X 10,5 4,7 * 2.
X = 19,9
? - Y adalah 10, Z adalah Y 1.
Y = 10,
Z = 11
Simbol seperti + - * / dalam ekspresi aritmatika adalah jenis khusus infiks
operator yang dikenal sebagai operator aritmetika. Tidak seperti operator digunakan di tempat lain di Prolog mereka tidak predikat tetapi fungsi yang mengembalikan nilai numerik. Seperti halnya angka-angka, variabel dan operator, ekspresi aritmatika dapat mencakup fungsi aritmatika, ditulis dengan argumen mereka dalam tanda kurung (yaitu bukan sebagai operator). Seperti operator aritmetika ini kembali nilai-nilai numerik, misalnya menemukan akar kuadrat dari 36:
? - X adalah sqrt (36).
X = 6
Operator aritmetik - dapat digunakan tidak hanya sebagai operator infiks biner
menunjukkan perbedaan dua nilai numerik, misalnya X-6, tetapi juga sebagai awalan unary operator untuk menunjukkan negatif dari sebuah nilai numerik, misalnya
? - X adalah 10, Y-X-2.
X = 10,
Y = -12
Tabel di bawah menunjukkan beberapa operator dan aritmatika aritmetika
fungsi yang tersedia dalam Prolog.
X + Y jumlah X dan Y
X-Y perbedaan dari X dan Y
X * Y produk X dan Y
X / Y hasil bagi X dan Y
X / / Y 'integer hasil bagi' dari X dan Y (hasilnya adalah dipotong ke
terdekat integer antara itu dan nol)
X ^ Y X ke Y kekuatan
-X negatif X
abs (X) nilai absolut X
sin (X) sinus X (untuk X diukur dalam derajat)
cos (X) kosinus X (untuk X diukur dalam derajat)
max (X, Y) yang lebih besar dari X dan Y
sqrt (X) akar kuadrat X
Operator dan Artithmetic 61
Contoh
? - X adalah 30, Y adalah 5, Z adalah X + Y + X * Y + sin (x).
X = 30,
Y = 5,
Z = 185,5
Meskipun merupakan predikat biasanya digunakan dalam cara yang dijelaskan di sini, pertama argumen juga bisa menjadi nomor atau sebuah variabel terikat dengan nilai numerik. Dalam kasus, nilai numerik dari dua argumen dihitung. Tujuan berhasil
jika ini adalah sama. Jika tidak, itu gagal.
? - X 7, X adalah 6 +1.
X = 7
? - 10 adalah 7 13-11 9.
tidak
? - 18 adalah 7 13-11 9.
ya
Unifikasi
Deskripsi sebelumnya dapat disederhanakan dengan mengatakan bahwa argumen kedua dari
yang adalah / 2 operator dievaluasi dan nilai ini kemudian disatukan dengan argumen pertama. Hal ini menggambarkan fleksibilitas konsep penyatuan.
(a) Jika argumen pertama adalah variabel terikat, ia terikat dengan nilai yang
Argumen kedua (sebagai efek samping) dan tujuan adalah berhasil.
(b) Jika argumen pertama adalah angka, atau variabel terikat dengan nilai numerik, itu dibandingkan dengan nilai argumen kedua. Jika mereka adalah sama, adalah tujuan
berhasil, selain itu gagal. Jika argumen pertama adalah atom, istilah majemuk, daftar, atau variabel terikat satu ini (tidak ada yang seharusnya terjadi), hasilnya adalah tergantung pada implementasi. Kemungkinan besar akan terjadi kesalahan. Perhatikan bahwa tujuan seperti X adalah X 1 akan selalu gagal, apakah X tidak terikat.
? - X adalah 10, X adalah X +1.
tidak
Untuk meningkatkan nilai oleh satu memerlukan pendekatan yang berbeda.
62 Logika Pemrograman Dengan Prolog
/ * Versi salah * /
meningkatkan (N):-N adalah N +1.
? - Meningkatkan (4).
tidak
/ * Benar versi * /
meningkatkan (N, M):-M adalah N +1.
? - Meningkat (4, X).
X = 5
Operator Precedence di Arithmetic Expressions
Bila ada lebih dari satu operator di sebuah ekspresi aritmatika, misalnya A + B * C-D, Prolog kebutuhan sarana menentukan urutan operator akan diterapkan.
Untuk operator dasar seperti + - * dan / itu sangat diinginkan bahwa ini adalah
adat 'matematika' order, yaitu ekspresi A + B * CD harus ditafsirkan
sebagai 'menghitung produk B dan C, tambahkan ke A dan kemudian kurangi D', bukan sebagai 'menambahkan A dan B, kemudian kalikan dengan C dan kurangi D '. Prolog mencapai hal ini dengan memberikan masing-masing operator numerik nilai didahulukan. Operator didahulukan relatif tinggi seperti * dan / diterapkan sebelum mereka yang didahulukan lebih rendah seperti + dan -. Operator dengan prioritas yang sama (misalnya + dan -, * dan /) diterapkan dari kiri ke kanan. Efeknya adalah untuk memberikan ekspresi seperti A + B * CD makna bahwa pengguna yang akrab dengan aljabar akan mengharapkan untuk memiliki, yaitu A + (B * C)-D. Jika urutan yang berbeda diperlukan evaluasi ini dapat dicapai dengan menggunakan kurung, e.g. X adalah (A + B) * (C-D). Ungkapan tanda kurung selalu dievaluasi terlebih dahulu.
Relational Operator
The infiks operator =: = = \ =>> = <=
relasional operator. Mereka digunakan untuk membandingkan nilai dari dua aritmatika
ekspresi. Tujuan berhasil jika nilai ekspresi pertama adalah sama dengan, tidak
sama dengan, lebih besar dari, lebih besar dari atau sama dengan, kurang dari atau kurang dari atau sama dengan
nilai dari ekspresi kedua, masing-masing. Kedua argumen harus angka,
terikat variabel atau ekspresi aritmetika (di mana setiap variabel terikat untuk
nilai numerik).
? - 88 15-3 =: = 110-5 * 2.
ya
? - 100 = \ = 99.
ya
Operator dan Artithmetic 63
Kesetaraan 4,3 Operator
Ada tiga jenis operator relasional untuk pengujian kesetaraan dan ketidaksetaraan
tersedia dalam Prolog. Tipe pertama digunakan untuk membandingkan nilai-nilai aritmatika ekspresi. Dua lainnya jenis tersebut digunakan untuk membandingkan istilah.
Aritmatika Expression Kesetaraan =: =
E1 =: = E2 berhasil jika ekspresi aritmetika mengevaluasi E1 dan E2 yang sama
nilai
Untuk memeriksa apakah suatu bilangan bulat ganjil atau bahkan kita dapat menggunakan checkeven / 1 predikat
didefinisikan di bawah ini.
checkeven (N):-M adalah N / / 2, N =: = 2 * M.
? - Checkeven (12).
ya
? - Checkeven (23).
tidak
? - Checkeven (-11).
tidak
? - Checkeven (-30).
ya
Integer hasil bagi para operator / / membagi argumen pertama dengan kedua dan
memotong hasilnya ke integer terdekat antara itu dan nol. Jadi 12 / / 2 adalah 6, 23 / / 2 adalah 11, -11 / / 2 adalah -5 dan -30 / / 2 adalah -15. Membagi sebuah integer dengan 2 menggunakan / / dan mengalikan itu dengan 2 lagi akan memberikan bilangan asli jika bahkan, tetapi tidak sebaliknya. Ekspresi aritmatika Ketidaksetaraan = \ = E1 = \ = E2 berhasil jika ekspresi aritmetika E1 dan E2 tidak mengevaluasi ke nilai sama
? - 10 = \ = 8 3.
ya
Logika Pemrograman Dengan Prolog
Persyaratan Identik ==
Kedua argumen dari operator == infiks harus istilah. Tujuan Term1 == Term2
berhasil jika dan hanya jika Term1 identik dengan Term2. Setiap variabel yang digunakan dalam istilah mungkin atau mungkin tidak sudah terikat, tetapi tidak ada variabel terikat sebagai akibat dari mengevaluasi tujuan.
? - Suka (X, Prolog) == suka (X, Prolog).
X = _
? - Suka (X, Prolog) == suka (Y, Prolog).
tidak
(X dan Y adalah variabel yang berbeda)
? - X adalah 10, pred1 (X) == pred1 (10).
X = 10
? - X == 0.
tidak
? - 6 4 == 3 +7.
tidak
Nilai sebuah ekspresi aritmatika hanya dievaluasi jika digunakan dengan adalah / 2
operator. Berikut 6 +4 hanyalah sebuah istilah dengan functor + dan argumen 6 dan 4. Ini sama sekali berbeda dari istilah 3 +7. Persyaratan Tidak Identik \ ==
Term1 \ == Term2 tes apakah Term1 tidak identik dengan Term2. Tujuan berhasil
jika Term1 == Term2 gagal. Selain itu gagal.
? - Pred1 (X) \ == pred1 (Y).
X = _,
Y = _
(Output menandakan bahwa baik X dan Y adalah terikat dan variabel yang berbeda.)
Syarat Identik Dengan Unifikasi = Istilah kesetaraan operator = adalah serupa dengan == dengan satu penting (dan sering sangat berguna) perbedaan. Tujuan Term1 = Term2 berhasil jika Term2 istilah Term1 dan menyatukan, yaitu ada beberapa cara untuk mengikat nilai-nilai variabel yang akan membuat persyaratan identik. Jika tujuan berhasil, seperti terjadi sebenarnya mengikat.
Logical Operator
Bagian ini memberikan gambaran singkat dari dua operator yang mengambil argumen yang
panggilan istilah, yaitu istilah yang dapat dianggap sebagai tujuan.
Operator yang tidak Operator awalan bukan / 1 dapat ditempatkan sebelum tujuan untuk memberikan yang pengingkaran. Itu tujuan menegasikan berhasil jika tujuan asli gagal dan gagal jika tujuan asli berhasil. Contoh berikut menggambarkan penggunaan tidak / 1. Diasumsikan bahwa database berisi satu klausul
anjing (fido).
? - Tidak anjing (fido).
tidak
? - Anjing (fred).
tidak
? - Tidak anjing (fred).
ya
? - X = 0, X adalah 0.
X = 0
? - X = 0, bukan X adalah 0.
tidak
The pemisahan Operator
The pemisahan operator; / 2 (ditulis sebagai karakter titik koma) digunakan untuk mewakili
'atau'. Ini adalah infiks operator yang membutuhkan dua argumen, yang keduanya adalah tujuan.
Tujuan1; Tujuan2 berhasil jika salah Tujuan1 atau Tujuan2 berhasil.
? - 6 <3; 7 adalah 5 +2.
ya
Operator dan Artithmetic 67
? - 6 * 6 =: = 36; 10 = 8 3.
ya
An expert system is software that attempts to provide an answer to a problem, or clarify uncertainties where normally one or more human experts would need to be consulted. Expert systems are most common in a specific problem domain, and is a traditional application and/or subfield of artificial intelligence. A wide variety of methods can be used to simulate the performance of the expert however common to most or all are 1) the creation of a so-called "knowledgebase" which uses some knowledge representation formalism to capture the Subject Matter Expert's (SME) knowledge and 2) a process of gathering that knowledge from the SME and codifying it according to the formalism, which is called knowledge engineering. Expert systems may or may not have learning components but a third common element is that once the system is developed it is proven by being placed in the same real world problem solving situation as the human SME, typically as an aid to human workers or a supplement to some information system.
Expert systems were introduced by Edward Feigenbaum, the first truly successful form of AI software.[1][2][3][4][5][6] The topic of expert systems has many points of contact with general systems theory, operations research, business process reengineering and various topics in applied mathematics and management science.
Expert systems topics
Chaining
Two methods of reasoning when using inference rules are backward chaining and forward chaining. Forward chaining starts with the data available and uses the inference rules to conclude more data until a desired goal is reached. An inference engine using forward chaining searches the inference rules until it finds one in which the if clause is known to be true. It then concludes the then clause and adds this information to its data. It would continue to do this until a goal is reached. Because the data available determines which inference rules are used, this method is also called data driven. Backward chaining starts with a list of goals and works backwards to see if there is data which will allow it to conclude any of these goals. An inference engine using backward chaining would search the inference rules until it finds one which has a then clause that matches a desired goal. If the if clause of that inference rule is not known to be true, then it is added to the list of goals. For example, suppose a rule base contains
Suppose a goal is to conclude that Fritz hops. The rule base would be searched and rule (2) would be selected because its conclusion (the then clause) matches the goal. It is not known that Fritz is a frog, so this "if" statement is added to the goal list. The rule base is again searched and this time rule (1) is selected because its then clause matches the new as certainty factors. A human, when reasoning, does not always conclude things with 100% confidence: he might venture, "If Fritz is green, then he is probably a frog" (after all, he might be a chameleon). This type of reasoning can be imitated by using numeric values called confidences. For example, if it is known that Fritz is green, it might be concluded with 0.85 confidence that he is a frog; or, if it is known that he is a frog, it might be concluded with 0.95 confidence that he hops. These numbers are probabilities in a Bayesian sense, in that they quantify uncertainty.
Expert system architecture
The following general points about expert systems and their architecture have been illustrated.
1. The sequence of steps taken to reach a conclusion is dynamically synthesized with each new case. It is not explicitly programmed when the system is built.
2. Expert systems can process multiple values for any problem parameter. This permits more than one line of reasoning to be pursued and the results of incomplete (not fully determined) reasoning to be presented.
3. Problem solving is accomplished by applying specific knowledge rather than specific technique. This is a key idea in expert systems technology. It reflects the belief that human experts do not process their knowledge differently from others, but they do possess different knowledge. With this philosophy, when one finds that their expert system does not produce the desired results, work begins to expand the knowledge base, not to re-program the procedures.
There are various expert systems in which a rulebase and an inference engine cooperate to simulate the reasoning process that a human expert pursues in analyzing a problem and arriving at a conclusion. In these systems, in order to simulate the human reasoning process, a vast amount of knowledge needed to be stored in the knowledge base. Generally, the knowledge base of such an expert system consisted of a relatively large number of "if then" type of statements that were interrelated in a manner that, in theory at least, resembled the sequence of mental steps that were involved in the human reasoning process.
Because of the need for large storage capacities and related programs to store the rulebase, most expert systems have, in the past, been run only on large information handling systems. Recently, the storage capacity of personal computers has increased to a point where it is becoming possible to consider running some types of simple expert systems on personal computers.
In some applications of expert systems, the nature of the application and the amount of stored information necessary to simulate the human reasoning process for that application is just too vast to store in the active memory of a computer. In other applications of expert systems, the nature of the application is such that not all of the information is always needed in the reasoning process. An example of this latter type application would be the use of an expert system to diagnose a data processing system comprising many separate components, some of which are optional. When that type of expert system employs a single integrated rulebase to diagnose the minimum system configuration of the data processing system, much of the rulebase is not required since many of the components which are optional units of the system will not be present in the system. Nevertheless, earlier expert systems require the entire rulebase to be stored since all the rules were, in effect, chained or linked together by the structure of the rulebase.
When the rulebase is segmented, preferably into contextual segments or units, it is then possible to eliminate portions of the Rulebase containing data or knowledge that is not needed in a particular application. The segmenting of the rulebase also allows the expert system to be run with systems or on systems having much smaller memory capacities than was possible with earlier arrangements since each segment of the rulebase can be paged into and out of the system as needed. The segmenting of the rulebase into contextual segments requires that the expert system manage various intersegment relationships as segments are paged into and out of memory during execution of the program. Since the system permits a rulebase segment to be called and executed at any time during the processing of the first rulebase, provision must be made to store the data that has been accumulated up to that point so that at some time later in the process, when the system returns to the first segment, it can proceed from the last point or rule node that was processed. Also, provision must be made so that data that has been collected by the system up to that point can be passed to the second segment of the rulebase after it has been paged into the system and data collected during the processing of the second segment can be passed to the first segment when the system returns to complete processing that segment.
The user interface and the procedure interface are two important functions in the information collection process.
End user
The end-user usually sees an expert system through an interactive dialog, an example of which follows:
Q. Do you know which restaurant you want to go to?
A. No
Q. Is there any kind of food you would particularly like?
A. No
Q. Do you like spicy food?
A. No
Q. Do you usually drink wine with meals?
A. Yes
Q. When you drink wine, is it French wine?
A. Yes
As can be seen from this dialog, the system is leading the user through a set of questions, the purpose of which is to determine a suitable set of restaurants to recommend. This dialog begins with the system asking if the user already knows the restaurant choice (a common feature of expert systems) and immediately illustrates a characteristic of expert systems; users may choose not to respond to any question. In expert systems, dialogs are not pre-planned. There is no fixed control structure. Dialogs are synthesized from the current information and the contents of the knowledge base. Because of this, not being able to supply the answer to a particular question does not stop the consultation.
Explanation system
Another major distinction between expert systems and traditional systems is illustrated by the following answer given by the system when the user answers a question with another question, "Why", as occurred in the above example. The answer is:
A. I am trying to determine the type of restaurant to suggest. So far Chinese is not a likely choice. It is possible that French is a likely choice. I know that if the diner is a wine drinker, and the preferred wine is French, then there is strong evidence that the restaurant choice should include French.
It is very difficult to implement a general explanation system (answering questions like "Why" and "How") in a traditional computer program. An expert system can generate an explanation by retracing the steps of its reasoning. The response of the expert system to the question WHY is an exposure of the underlying knowledge structure. It is a rule; a set of antecedent conditions which, if true, allow the assertion of a consequent. The rule references values, and tests them against various constraints or asserts constraints onto them. This, in fact, is a significant part of the knowledge structure. There are values, which may be associated with some organizing entity. For example, the individual diner is an entity with various attributes (values) including whether they drink wine and the kind of wine. There are also rules, which associate the currently known values of some attributes with assertions that can be made about other attributes. It is the orderly processing of these rules that dictates the dialog itself.
Expert systems versus problem-solving systems
The principal distinction between expert systems and traditional problem solving programs is the way in which the problem related expertise is coded. In traditional applications, problem expertise is encoded in both program and data structures. In the expert system approach all of the problem related expertise is encoded in data structures only; no problem-specific information is encoded in the program structure. This organization has several benefits.
An example may help contrast the traditional problem solving program with the expert system approach. The example is the problem of tax advice. In the traditional approach data structures describe the taxpayer and tax tables, and a program in which there are statements representing an expert tax consultant's knowledge, such as statements which relate information about the taxpayer to tax table choices. It is this representation of the tax expert's knowledge that is difficult for the tax expert to understand or modify.
In the expert system approach, the information about taxpayers and tax computations is again found in data structures, but now the knowledge describing the relationships between them is encoded in data structures as well. The programs of an expert system are independent of the problem domain (taxes) and serve to process the data structures without regard to the nature of the problem area they describe. For example, there are programs to acquire the described data values through user interaction, programs to represent and process special organizations of description, and programs to process the declarations that represent semantic relationships within the problem domain and an algorithm to control the processing sequence and focus.
The general architecture of an expert system involves two principal components: a problem dependent set of data declarations called the knowledge base or rule base, and a problem independent (although highly data structure dependent) program which is called the inference engine.
Individuals involved with expert systems
There are generally three individuals having an interaction with expert systems. Primary among these is the end-user; the individual who uses the system for its problem solving assistance. In the building and maintenance of the system there are two other roles: the problem domain expert who builds and supplies the knowledge base providing the domain expertise, and a knowledge engineer who assists the experts in determining the representation of their knowledge, enters this knowledge into an explanation module and who defines the inference technique required to obtain useful problem solving activity. Usually, the knowledge engineer will represent the problem solving activity in the form of rules which is referred to as a rule-based expert system. When these rules are created from the domain expertise, the knowledge base stores the rules of the expert system.
Inference rule
An understanding of the "inference rule" concept is important to understand expert systems. An inference rule is a statement that has two parts, an if clause and a then clause. This rule is what gives expert systems the ability to find solutions to diagnostic and prescriptive problems. An example of an inference rule is:
If the restaurant choice includes French, and the occasion is romantic,
Then the restaurant choice is definitely Paul Bocuse.
An expert system's rulebase is made up of many such inference rules. They are entered as separate rules and it is the inference engine that uses them together to draw conclusions. Because each rule is a unit, rules may be deleted or added without affecting other rules (though it should affect which conclusions are reached). One advantage of inference rules over traditional programming is that inference rules use reasoning which more closely resemble human reasoning.
Thus, when a conclusion is drawn, it is possible to understand how this conclusion was reached. Furthermore, because the expert system uses knowledge in a form similar to the expert, it may be easier to retrieve this information from the expert.
Procedure node interface
The function of the procedure node interface is to receive information from the procedures coordinator and create the appropriate procedure call. The ability to call a procedure and receive information from that procedure can be viewed as simply a generalization of input from the external world. While in some earlier expert systems external information has been obtained, that information was obtained only in a predetermined manner so only certain information could actually be acquired. This expert system, disclosed in the cross-referenced application, through the knowledge base, is permitted to invoke any procedure allowed on its host system. This makes the expert system useful in a much wider class of knowledge domains than if it had no external access or only limited external access.
In the area of machine diagnostics using expert systems, particularly self-diagnostic applications, it is not possible to conclude the current state of "health" of a machine without some information. The best source of information is the machine itself, for it contains much detailed information that could not reasonably be provided by the operator.
The knowledge that is represented in the system appears in the rulebase. In the rulebase described in the cross-referenced applications, there are basically four different types of objects, with associated information present.
Classes—these are questions asked to the user.
Parameters—a parameter is a place holder for a character string which may be a variable that can be inserted into a class question at the point in the question where the parameter is positioned.
Procedures—these are definitions of calls to external procedures.
Rule Nodes—The inferencing in the system is done by a tree structure which indicates the rules or logic which mimics human reasoning. The nodes of these trees are called rule nodes. There are several different types of rule nodes.
The rulebase comprises a forest of many trees. The top node of the tree is called the goal node, in that it contains the conclusion. Each tree in the forest has a different goal node. The leaves of the tree are also referred to as rule nodes, or one of the types of rule nodes. A leaf may be an evidence node, an external node, or a reference node.
An evidence node functions to obtain information from the operator by asking a specific question. In responding to a question presented by an evidence node, the operator is generally instructed to answer "yes" or "no" represented by numeric values 1 and 0 or provide a value of between 0 and 1, represented by a "maybe."
Questions which require a response from the operator other than yes or no or a value between 0 and 1 are handled in a different manner.
A leaf that is an external node indicates that data will be used which was obtained from a procedure call.
A reference node functions to refer to another tree or subtree.
A tree may also contain intermediate or minor nodes between the goal node and the leaf node. An intermediate node can represent logical operations like And or Or.
The inference logic has two functions. It selects a tree to trace and then it traces that tree. Once a tree has been selected, that tree is traced, depth-first, left to right.
The word "tracing" refers to the action the system takes as it traverses the tree, asking classes (questions), calling procedures, and calculating confidences as it proceeds.
As explained in the cross-referenced applications, the selection of a tree depends on the ordering of the trees. The original ordering of the trees is the order in which they appear in the rulebase. This order can be changed, however, by assigning an evidence node an attribute "initial" which is described in detail in these applications. The first action taken is to obtain values for all evidence nodes which have been assigned an "initial" attribute. Using only the answers to these initial evidences, the rules are ordered so that the most likely to succeed is evaluated first. The trees can be further re-ordered since they are constantly being updated as a selected tree is being traced.
It has been found that the type of information that is solicited by the system from the user by means of questions or classes should be tailored to the level of knowledge of the user. In many applications, the group of prospective uses is nicely defined and the knowledge level can be estimated so that the questions can be presented at a level which corresponds generally to the average user. However, in other applications, knowledge of the specific domain of the expert system might vary considerably among the group of prospective users.
One application where this is particularly true involves the use of an expert system, operating in a self-diagnostic mode on a personal computer to assist the operator of the personal computer to diagnose the cause of a fault or error in either the hardware or software. In general, asking the operator for information is the most straightforward way for the expert system to gather information assuming, of course, that the information is or should be within the operator's understanding. For example, in diagnosing a personal computer, the expert system must know the major functional components of the system. It could ask the operator, for instance, if the display is a monochrome or color display. The operator should, in all probability, be able to provide the correct answer 100% of the time. The expert system could, on the other hand, cause a test unit to be run to determine the type of display. The accuracy of the data collected by either approach in this instance probably would not be that different so the knowledge engineer could employ either approach without affecting the accuracy of the diagnosis. However, in many instances, because of the nature of the information being solicited, it is better to obtain the information from the system rather than asking the operator, because the accuracy of the data supplied by the operator is so low that the system could not effectively process it to a meaningful conclusion.
In many situations the information is already in the system, in a form of which permits the correct answer to a question to be obtained through a process of inductive or deductive reasoning. The data previously collected by the system could be answers provided by the user to less complex questions that were asked for a different reason or results returned from test units that were previously run.
User interface
The function of the user interface is to present questions and information to the user and supply the user's responses to the inference engine.
Any values entered by the user must be received and interpreted by the user interface. Some responses are restricted to a set of possible legal answers, others are not. The user interface checks all responses to insure that they are of the correct data type. Any responses that are restricted to a legal set of answers are compared against these legal answers. Whenever the user enters an illegal answer, the user interface informs the user that his answer was invalid and prompts him to correct it.
Application of expert systems
Expert systems are designed and created to facilitate tasks in the fields of accounting, medicine, process control, financial service, production, human resources etc. Indeed, the foundation of a successful expert system depends on a series of technical procedures and development that may be designed by certain technicians and related experts.
A good example of application of expert systems in banking area is expert systems for mortgages. Loan departments are interested in expert systems for mortgages because of the growing cost of labour which makes the handling and acceptance of relatively small loans less profitable. They also see in the application of expert systems a possibility for standardised, efficient handling of mortgage loan, and appreciate that for the acceptance of mortgages there are hard and fast rules which do not always exist with other types of loans.
While expert systems have distinguished themselves in AI research in finding practical application, their application has been limited. Expert systems are notoriously narrow in their domain of knowledge—as an amusing example, a researcher used the "skin disease" expert system to diagnose his rustbucket car as likely to have developed measles—and the systems were thus prone to making errors that humans would easily spot. Additionally, once some of the mystique had worn off, most programmers realized that simple expert systems were essentially just slightly more elaborate versions of the decision logic they had already been using. Therefore, some of the techniques of expert systems can now be found in most complex programs without any fuss about them.
An example, and a good demonstration of the limitations of, an expert system used by many people is the Microsoft Windowsoperating systemtroubleshooting software located in the "help" section in the taskbar menu. Obtaining expert/technical operating system support is often difficult for individuals not closely involved with the development of the operating system. Microsoft has designed their expert system to provide solutions, advice, and suggestions to common errors encountered throughout using the operating systems.
Another 1970s and 1980s application of expert systems — which we today would simply call AI — was in computer games. For example, the computer baseball games Earl Weaver Baseball and Tony La Russa Baseball each had highly detailed simulations of the game strategies of those two baseball managers. When a human played the game against the computer, the computer queried the Earl Weaver or Tony La Russa Expert System for a decision on what strategy to follow. Even those choices where some randomness was part of the natural system (such as when to throw a surprise pitch-out to try to trick a runner trying to steal a base) were decided based on probabilities supplied by Weaver or La Russa. Today we would simply say that "the game's AI provided the opposing manager's strategy."
Advantages and disadvantages
Advantages:
Provides consistent answers for repetitive decisions, processes and tasks
Holds and maintains significant levels of information
Encourages organizations to clarify the logic of their decision-making
Never "forgets" to ask a question, as a human might
Can work round the clock
Can be used by the user more frequently
A multi-user expert system can serve more users at a time
Disadvantages:
Lacks common sense needed in some decision making
Cannot make creative responses as human expert would in unusual circumstances
Domain experts not always able to explain their logic and reasoning
Errors may occur in the knowledge base, and lead to wrong decisions
Cannot adapt to changing environments, unless knowledge base is changed
Types of problems solved by expert systems
Expert systems are most valuable to organizations that have a high-level of know-how experience and expertise that cannot be easily transferred to other members. They are designed to carry the intelligence and information found in the intellect of experts and provide this knowledge to other members of the organization for problem-solving purposes.
Typically, the problems to be solved are of the sort that would normally be tackled by a medical or other professional. Real experts in the problem domain (which will typically be very narrow, for instance "diagnosing skin conditions in human teenagers") are asked to provide "rules of thumb" on how they evaluate the problems, either explicitly with the aid of experienced systems developers, or sometimes implicitly, by getting such experts to evaluate test cases and using computer programs to examine the test data and (in a strictly limited manner) derive rules from that. Generally, expert systems are used for problems for which there is no single "correct" solution which can be encoded in a conventional algorithm — one would not write an expert system to find shortest paths through graphs, or sort data, as there are simply easier ways to do these tasks.
Simple systems use simple true/false logic to evaluate data. More sophisticated systems are capable of performing at least some evaluation, taking into account real-world uncertainties, using such methods as fuzzy logic. Such sophistication is difficult to develop and still highly imperfect.
Expert Systems Shells or Inference Engine
A shell is a complete development environment for building and maintaining knowledge-based applications. It provides a step-by-step methodology, and ideally a user-friendly interface such as a graphical interface, for a knowledge engineer that allows the domain experts themselves to be directly involved in structuring and encoding the knowledge. Many commercial shells are available, one example being eGanges which aims to remove the need for a knowledge enginee
Rule-based Expert Systems
A rule-based expert system is an expert system (see intro) which works as a production system in which rules encode expert knowledge.
Most expert systems are rule-based. Alternatives are
frame-based - knowledge is associated with the objects of interest and reasoning consists of confirming expectations for slot values. Such systems often include rules too.
model-based, where the entire system models the real world, and this deep knowledge is used to e.g. diagnose equipment malfunctions, by comparing model predicted outcomes with actual observed outcomes
case-based - previous examples (cases) of the task and its solution are stored. To solve a new problem the closest matching case is retrieved, and its solution or an adaptation of it is proposed as the solution to the new problem.
Typical Expert System Architecture
(from Luger and Stubblefield)
Data-driven Rule-based Expert Systems
Use Forward Chaining:
Given a certain set of facts in WM, use the rules to generate new facts until the desired goal is reached.
To forward chain the inference engine must:
1.Match the condition patterns of rules against facts in working memory.
2.If there is more than one rule that could be used (that could "fire"), selectwhich one to apply (this is called conflict resolution)
3.Apply the rule, maybe causing new facts to be added to working memory
4.Halt when some useful (or goal) conclusion is added to WM (or until all possible conclusions have been drawn.)
Goal-driven Rule-based Expert Systems
Use Backward Chaining:
Work backwards from ahypothesised goal, attempting to prove it by linking the goal to the initial facts.
To backward chain from a goal in WM the inference engine must:
1.Select rules with conclusions matching the goal.
2.Replace the goal by the rule's premises. These become sub-goals.
3.Work backwards till all sub-goals are known to be true -
either they are facts (in WM)
orthe user provides the information.
Example
A production system IDENTIFIER, which identifies animals.
R1IFthe animal has hair THEN it is a mammal
R2IFthe animal gives milk THEN it is a mammal
R3IFthe animal has feathers THENit is a bird
R4IFthe animal flies the animal lays eggs THENit is a bird
R5IFthe animal is a mammal the animal eats meat THENit is a carnivore
R6IFthe animal is a mammal the animal has pointed teeth the animal has claws the animal's eyes point forward THENit is a carnivore
R7IFthe animal is a mammal the animal has hooves THENit is an ungulate
R8IFthe animal is a mammal the animal chews cud THENit is an ungulateAND it is even-toed
R9IFthe animal is a carnivore the animal has a tawny colour the animal has dark spots THENit is a cheetah
R10IFthe animal is a carnivore the animal has a tawny colour the animal has black stripes THENit is a tiger
R11IFthe animal is an ungulate the animal has long legs the animal has a long neck THENit is a giraffe
R12IFthe animal is an ungulate the animal has a white colour the animal has black stripes THENit is a zebra
R13IFthe animal is a bird the animal does not fly the animal has long legs the animal has a long neck the animal is black and white THENit is an ostrich
R14IFthe animal is a bird the animal does not fly the animal swims the animal is black and white THENit is a penguin
R15IFthe animal is a bird the animal is a good flier THENit is an albatross
PROBLEM:
Given these facts in working memory initially:
the animal gives milk
the animal chews its cud
the animal has long legs
the animal has a long neck
Establish by forward chaining that the animal is a giraffe.
Given the facts that:
the animal has hair
the animal has claws
the animal has pointed teeth
the animal's eyes point forward
the animal has a tawny colour
the animal has dark spots
Establish by backward chaining that the animal is a cheetah.
[HINT: start with R9, first subgoal : the animal is a carnivore etc.]
Goal-driven search is suggested if:
·A goal or hypothesis is given in the problem statement or can be easily formulated
(theorem-proving, diagnosis hypothesis testing).
·There are a large number of rules that match the facts, producing a large number of conclusions - choosing a goal prunes the search space.
·Problem data are not given (or easily available) but must be acquired as necessary (e.g. medical tests).
Data-driven search is suggested if:
·All or most of the data is given in the problem statement (interpretation problems)
·Large number of potential goals but few achievable in a particular problem instance.
·It is difficult to formulate a goal or hypothesis.
Data-driven search can appear aimless but produces all solutions to a problem (if desired)
Mixed reasoning is also possible - facts get added to the WM and sub-goals get created until all the sub-goals are present as facts.
Explanation Facility in Expert Systems
Rule-based systems can be designed to answer questions like
WHY do you want to know this fact ?(i.e. where is the reasoning going?)
HOW did you deduce this fact ? (i.e. how did we get here?)
Explanation facilities are useful for debugging a rulebase but also for instilling confidence in users of the ES.
A tracer module records the rules that have been used. To answer HOW questions these rules are searched for one where the fact in question is a consequent (action/then part).
(see MYCIN case study)
The production system architecture provides the essential basis for explanation facility, and the facility contributes to the success and popularity of rule-based ES.
Handling Uncertainty in Expert Systems
Uncertainty arises from abductive rules, heuristic rules or missing or unreliable data.
ABDUCTION: ES rules are frequently not sound logically, but are abductive.The abductive rule
if the engine does not turn over and the lights do not come on thenthe problem is battery or cables.
is not always right, but would be typical of a car diagnosis system. Its converse, while not so useful is logically sound :
if the problem is battery or cables then the engine does not turn over and the lights do not come on
Abductive reasoning is very important in diagnosis - diseases cause symptoms, but we have sympoms and want to work back to the cause.
To reason with uncertainty, we attach confidence measures to facts and to rules. We need mechanisms to combine these measures.
Handling uncertainty in rule-based expert systems
Three situations need to be handled.
(1) If A and B and C then …
If my confidence in A is x and in B is y and in C is z how confident am I about their conjunction (A and B and C)?
(2) If D then E
If my confidence in D is x how confident can I be in E?
(3) If the same fact F is deduced from (two) separate rules with confidences x and y, how confident am I in F?
A. Simple (Conservative) Rules
(1)Confidence in the conjunction is
min (x, y z)a chain is as strong as its weakest link
(2)Confidence in rule conclusion is
x . aais the rule's attenuation factor
(3)Confidence in the multiply derived fact is
max (x, y)a conclusion is no more certain than the strongest supporting argument.
B. Bayesian Probability Theory Based
Confidence measures are probabilities.
(1) Confidence in conjunction is = x . y . z
(2) Confidence in a rule is based on Bayes theorem
(there should be a summation symbol on the bottom line)
which relates
P(Di|S)the probability of having disease i if you have the symptom S,
to measures of
P(Di) the probability of having disease i in general,
P(S|Di) the probability of having the symptom S if you have disease i, and
P(S|Dk)for all possible diseases Dk, the probability of having symptom S if you have diseases Dk.
(Diseases are hypotheses; symptoms are evidence.)
Difficulties with Bayes' Theorem:
Bayes theorem assumes that relationships between evidence and hypotheses are independent of one another. (e.g. the probability of someone who has flu having a sore throat and the probability of someone who has flu having a temperature, should be independent. But are they ?)
Probabilities should be collected statistically, and kept up to date with all new discoveries about diseases and their symptoms. This is impractical.
Bayes-based probability is not a good way to model uncertainty in medical diagnosis systems.
Nonetheless, doctors feel that they can make informed assessment of their confidence in their heuristic rules.
C. Stanford Certainty Factor Algebra
(See also MYCIN notes.)
CF (H|E) is the certainty factor of hypothesis H given evidence E.
-1<CF (H|E)<1
strong evidencestrong evidence
against the hypothesisfor the hypothesis
(1) Confidence in the conjunction is
min (x, y, z)
(2) Confidence in rule conclusion is
x . CF (R)CF (R) is certainty factor associated with this conclusion of the rule.
(3) Confidence in the multiply derived fact is
x + y - (x * y)if both are positive x + y + (x * y)if both are negative
?=x + y.otherwise 1 - min (|x|, |y|)
Note: These formulae leave-1 < CF < 1
Combining contradictory rules cancels out the CF
CFs increase montonically as we add evidence
Other theories for handling uncertainty
Zadeh's Fuzzy Sets - a theory of possibility that tries to measure the vagueness of English statements (e.g. "Ann is tall")
Dempster-Schafer Belief Functions
All these theories are numeric which does not seem to be the way humans reason with uncertainty.
Non-monotonic reasoning is a completely different approach which allows you to proceed with the most reasonable assumption based on uncertain information and to change the assumption (and conclusions that have arisen from it) if the assumption becomes unreasonable. (Truth maintenance systems.)
(Monotonic reasoning systems only allow knowledge/info to be added, whereas humans delete information that is found tobe untrue.)
Expert System Shells
An expert system shell is an expert system with an empty knowledge base, i.e.
An inference engine
User interface module
Tracer/explanation module
Knowledge base (rule) editor
Etc.
EXSYS is a shell, KEE, OPS5, KAS, …
EMYCIN is the shell of MYCIN
It is important to start with a shell with a suitable control strategy.
Recent trends are towards shells that include multiple engines, making them more flexible.
Case Study : MYCIN
An example Goal-driven Medical Diagnostic Expert System
(taken from Luger and Stubblefield section 8.4)
Purpose:
·Diagnose and recommend treatment for meningitis and bacteremia (more quickly than definitive lab tests).
·Explore how human experts reason with missing and incomplete information.
History
mid-late '70s
50 person years
Stanford medical school
Comprehensively evaluated
Never used clinically
Widely documented ("Rule-based expert systems" Buchanan and Shortliffe, Stanford 1984, a collection of publications on MYCIN).
Representation
Facts:
(ident organism-1 klebsiella .25)
there is evidence (.25) that the identity of organism-1 is klebsiella
(sensitive organism-1 penicillin -1.0)
it is known that org-1 is NOT sensitive to penicillin.
If the infection is primary bacteremia and the site of the culture is a sterile one and the suspected portal of entry is GI tract then there is suggestive evidence (.7) that infection is bacteroid.
Consequent (then-part) can
§Add facts to database
§Write to terminal
§Change a value in a fact, or its certainty
§Lookup a table
§Execute a LISP procedure
Operation:
Routine questions
Specific questions about symptoms
Depth-firstgoal driven consideration
of each "known" organism
Terminates "depth-search" when certainty measures get too low.
Selection criterion is to maximise certainty - if a rule can prove a goal with certainty 1 then no more rules need be considered.
Goal-driven so that questions appear to be directed - less frustrating, more confidence building for the user.
English-like interaction (see handout).
Answers WHY by printing the rule under consideration.
Exhaustive consideration of possible infections - patient may have more than one.
Uncertainty in MYCIN
IfA: stain is gram positive
and B: morphology is coccus
and C: growth conformation is chains
then there is suggestive evidence (0.7) that
H: organism is streptococcus
0.7 is the measure of increase of belief (MB) of H given evidence A and B and C.
MB ranges 0 to 1.
Assigned by subjective judgement usually.
As a guide:
1if P(H)=1
MB(H|E) = max[P(H|E),P(H)] - P(H)otherwise
max[1,0] - P(H)
Measures of disbelief also allowed. These also range 0 to 1.
1if P(H)=1
MD(H|E) = min[P(H|E),P(H)] - P(H)otherwise
min[1,0] - P(H)
Note if E and H are independent, E does not change the belief in H:
P(H|E) = P(H), so MB = MD = 0.
MB(H|E) should only be 1 if E logically implies H.
Initially each hypothesis has MB=MD=0.
As evidence is accumulated these are updated.
At the end a certainty factor CF = MB-MD is computed for each hypothesis.
The largest absolute CF values used to determine appropriate therapy. Weakly supported hypotheses |CF| < 2 are ignored.
MYCIN's handling of uncertainty is an ad-hoc method (based on probability). But it seems to work as well as more formal approaches.